
MLOps란?

MLOps란 머신 러닝(Machine Learning)과 운영(Operations)을 합친 용어로
프로덕션
환경에서 머신 러닝(ML) 모델이 지속적이고 안정적으로 배포되도록 유지, 관리, 모니터링 해주는 것입니다.
MLOps는 머신러닝 모델 개발과 운영을 통합해 ML 시스템을 자동으로 유지, 관리, 운영합니다.
MLOps의 대상은 머신 러닝 모델을 개발하는 것뿐만 아니라 데이터를 수집하고 분석하는 단계와 학습하여 배포하는 과정, 즉 전체 AI 생애 주기가 포함됩니다.
출처 : elice https://elice.io/ko/newsroom/whats_mlops
개발에도 DevOps가 있듯이 머신러닝 개발에도 MLOps가 있다.
인공지능 개발에는 데이터 전처리, 학습, 평가, 추론, 모니터링 등 복잡한 단계가 필요하고 MLOp를 통해 자동화 할 수 있다. 인공지능 모델 개발의 생명주기들을 자동화하여 데이터 과학자, 데이터 엔지니어, SW 엔지니어간 협업에 필요한 비용을 낮출 수 있다.
인공지능 모델을 한 번이라도 개발해 본 사람이라면 알겠지만, 모델 학습시 데이터 전처리, 학습, 튜닝, 추론을 로컬 머신에서 관리하게 되면 그 복잡성이 너무 크다. 또, git과 같은 코드 형상관리 프로그램으로 커버하기 어려운 부분이 있다.
프로덕션 환경에서 이를 자동화하고 데이터를 더 잘 관리할 수 있게 하는 것이 MLOps라고 이해하고 있다.

보통의 시스템과 ML 시스템의 차이는 데이터에 있다.
전통적인 시스템은 코드가 있고, 그 코드가 작동하는 환경으로 구성되는 반면 오른쪽 그림에서 처럼 ML기반 시스템은 그 중간에 모델 학습의 단계가 추가적으로 필요하고 각 단계별로 데이터가 추가된다. 데이터를 검증하는 로직도 필요하고, 데이터를 이용해서 모델을 재학습하거나 결과를 얻는다.
주로 기업들이 사용하고 도입하는 ML서비스는 말그대로 Deep Learning이 아니라 ML 이어서 데이터를 검증하거나 feature를 추출하여 저장하는 추가 단계가 필요한 것이 아닐까 한다. → 이미지 추론 서비스에서는 feature store가 필요한가, 검증을 어떻게 자동화하는가에서 나온 생각. 이미지는 검증하려면 사람의 눈으로 해야하지 않을까? CT를 아직 잘 몰라서 그럴지도
ML 서비스의 기본
MLOps에 대해서 알아보기 전에 ML을 서비스하기 위해 기본적으로 필요한 요소를 알아볼 필요가 있다.
토스 ML팀의 고석현님의 발표에서 ML 서비스의 기본을 다음과 같이 정의했다.
Ops를 위해 여러 기술들이 추가되어도 ML서비스가 기본으로 갖추어야할 요소는 다음의 세 가지이다.
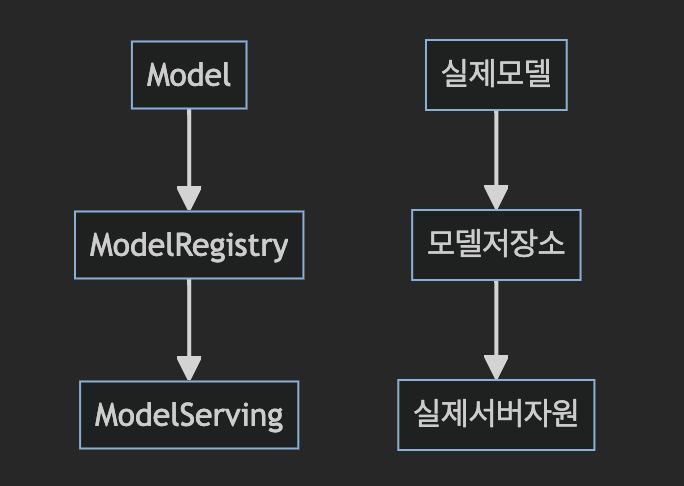
모델 저장소는 말그대로 학습한 모델을 저장하는 곳으로 S3, RDB, 나스가 될 수 있다.
MLOps 아키텍처
구글은 2015년부터 MLOps의 필요성을 이야기했다. 그리고 0~2단계, 총 3단계로 나누어 MLOps 아키텍처를 설명한다.
AWS나 Azure에서 각자의 MLOps 아키텍처를 가지고 있지만 크게 다르지 않다.
2. Levels of MLOps | MLOps for ALL
Levels of MLOps
mlops-for-all.github.io
Level1 : 수동
모든 단계를 수동으로 하는 것을 말한다.
CI/CD, 성능 모니터링이 이루어지지 않고, 존재하는 데이터도 offline data로 배치성 데이터이다. 데이터 과학자와 엔지니어의 영역이 나뉘어있다.
데이터 과학자가 학습한 모델을 모델 레지스트리에 저장하면 엔지니어가 서빙하는 구조이다.
위에서 알아보았던 ML서비스의 기본이 이 단계쯤 되지 않을까한다.

이 단계에서는 자동화 된 것이 없기 때문에 학습환경과 서빙환경이 달라서 ‘안되는데요?’ ‘저는 됐는데요?’ 상황이 발생할 수 있고, 그 환경을 a to z 까지 맞추기위해 노력해야한다. (종속성 맞출 생각하니까 벌써부터 화딱지가 난다)
Level2: 파이프라인 자동화와 Continous Training
Level 1에서는 파이프라인이 자동화 된다. 데이터 과학자가 모델 개발에 사용한 프로세스 및 환경을 동일하게 제공한다.
또한 여기에 새로운 데이터를 사용하여 프로덕션 모델이 자동으로 학습하는 CT(Continuous Training)개념이 추가된다.
Level 0에서는 학습된 모델만을 배포했다면 Level 1에서는 전체 파이프라인이 배포된다.

특징 (출처 : https://jaemunbro.medium.com/mlops가-무엇인고-84f68e4690be)
- Rapid experiment : 실험을 빠르게 반복하고, 전체 파이프라인을 프로덕션으로 빠르게 배포
- 개발 환경에서 쓰인 파이프라인이 운영 환경에도 그대로 쓰임. DevOps의 MLOps 통합에 있어 핵심적인 요소
- 프로덕션 모델의 CT(Continuous Training) : 새로운 데이터를 사용하여 프로덕션 모델이 자동으로 학습
- CD: 새로운 데이터로 학습되고 검증된 모델이 지속적으로 배포됨.
- Level 0에서는 학습된 모델만을 배포했다면 Level 1에서는 전체 파이프라인이 배포
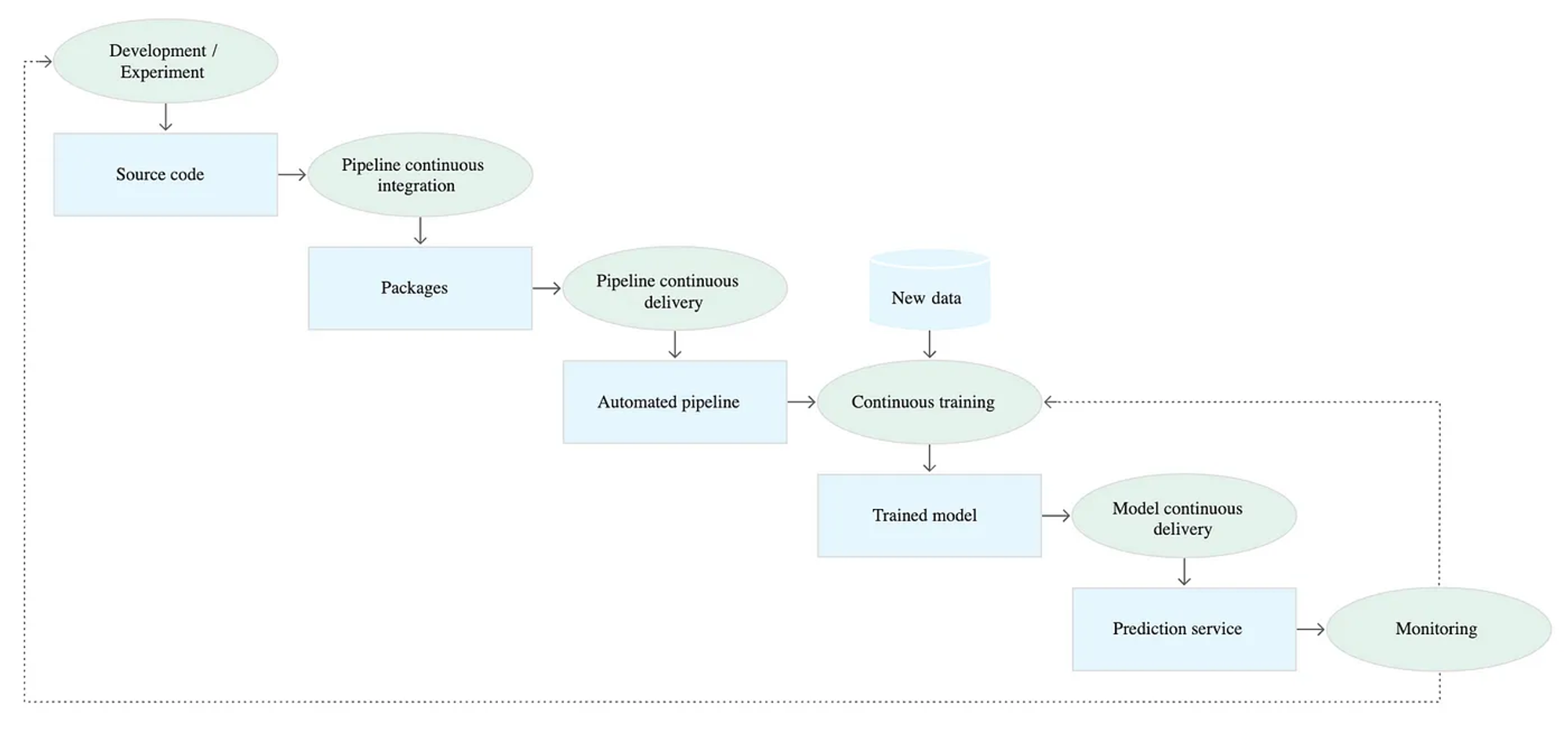
Level 2 : CI/CD의 자동화
학습 파이프라인의 소스코드 CI/CD 자동화까지 이루어지는 단계이다. 실험과 배포의 통합으로 데이터 과학자가 바로 실험 결과를 배포 가능하다.

[Continuous Integration]
파이프라인과 구성요소는 커밋되거나 소스 레포지토리로 푸시될 때 빌드, 테스트, 패키징된다. 아래와 같은 테스트가 포함될 수 있다.
- 특성 추출 로직을 테스트 모델에 구현된 메소드를 단위 테스트 모델 학습이 수렴하는지 테스트
- 모델 학습에서 0으로 나누거나 작은 값 또는 큰 값을 조작하여 NaN 값을 생성하지 않는지 테스트
- 파이프라인의 각 구성요소가 예상된 아티팩트를 생성하는지 테스트
- 파이프라인 구성요소간 통합 테스트
[Continuous Delivery]
- 모델 배포 전 모델과 대상 인프라 호환성 확인. (패키지 호환 여부/메모리/컴퓨팅 자원등)
- 서비스 API 호출 테스트
- QPS 및 지연 시간과 같은 서비스 부하 테스트
(출처 : https://jaemunbro.medium.com/mlops가-무엇인고-84f68e4690be)
위 글에서 정리된 2단계 mlops의 CI/CD 단계이다.
1단계에서는 모델을 재학습하고 빠르게 배포하는 로직에 집중되어있었던 반면 2단계에서는 코드단까지의 CI/CD가 이루어지는 것을 알 수 있다. DevOps에서 처럼 각 요소들을 테스트한다.
MLOps를 제공하는 오픈 소스
MLOps를 제공하는 플랫폼은 매우 다양한다. AWS sagemaker, Airflow 등
그 중 오픈소스 중 두 가지(MLflow, kubeflow)에 대해서 알아보았다.
MLflow
데이터 브릭스에서 개발한 End to End로 머신러닝 라이프 사이클을 관리할 수 있는 오픈소스이다.
Docs: https://mlflow.org/docs/latest/index.html
ml에 필요한 4가지 기능을 제공한다.
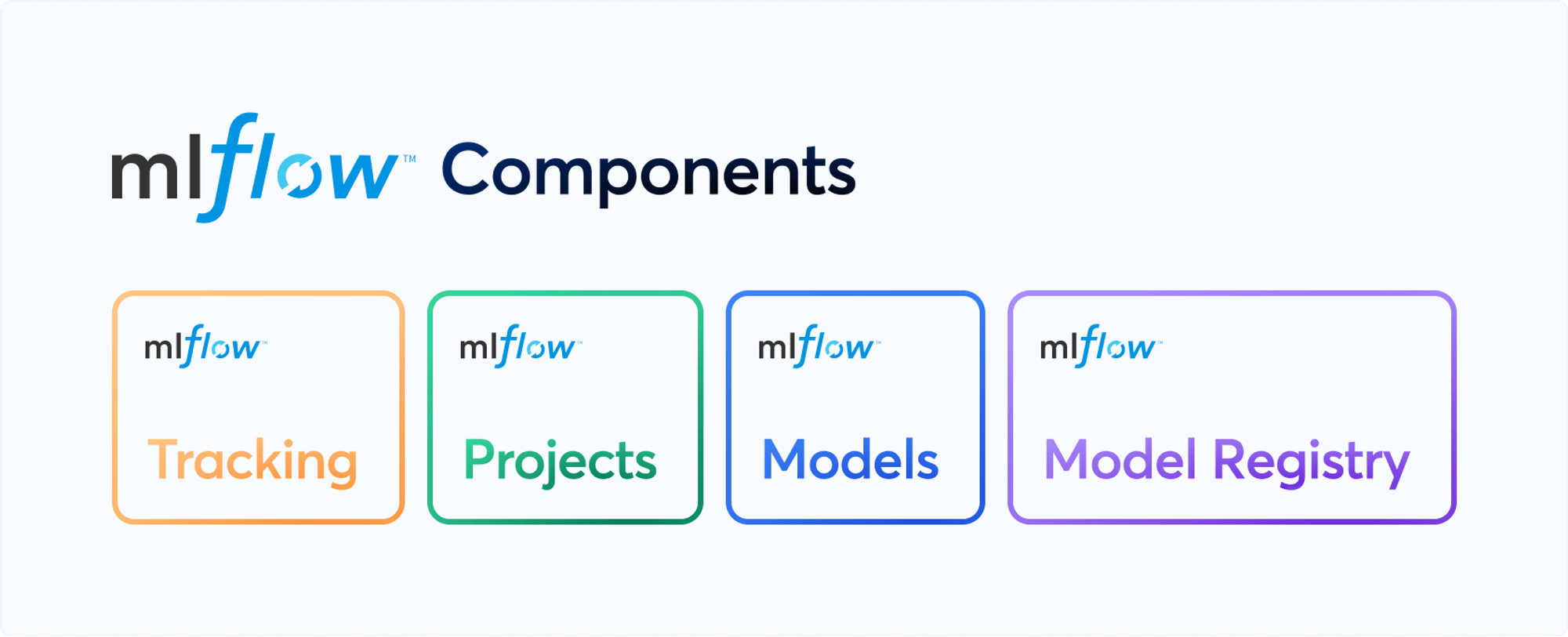
[제공하는 주요 기능]
- tracking : record and query experiments : code, data, config, results / 코드, 데이터, 설정, 결과 등의 실험 기록 및 조회
- projects : packaging format for reproducible runs on any platform / 어떤 플랫폼에서도 재현 가능한 실행을 위한 패키징 형식
- models : general format that standardizes deployment paths / 배포 경로를 표준화하는 일반적인 형식
- model registry : centralized and collaboartive model lifecycle management / 중앙 집중화되고 협력적인 모델 생명주기 관리
특징
- 설치와 사용이 쉽다.
- 다양한 integration을 제공해서 프레임워크에 종속되지 않고 이용할 수 있다. (onnx도 제공한다.)

- Databricks, Azure, Docker, AWS 등에서 배포가 가능하다.

- 하나의 host에서 하나의 모델만 배포할 수 있다. (추론용 endpoint가 /invocations 이다.)
간단히 사용해 본 후 남기는 몇 가지 명령어 메모 😁
# local server on
mlflow server --host 127.0.0.1 --port 8080
# model serving
mlflow models serve -m models:/sk-learn-random-forest-reg-model/2 -h 0.0.0.0 -p 8081
# response inference
curl <http://127.0.0.1:8081/invocations> -H "Content-Type:application/json" --data '{"inputs" : [[-0.955945 , -0.34598178, -0.46359597, 0.48148147]]}'
mlflow.set_tracking_uri(uri="<http://127.0.0.1:8080>")
# Supported URI schemes are: ['', 'file', 'databricks', 'databricks-uc', 'http', 'https', 'postgresql', 'mysql', 'sqlite', 'mssql'].MLFLOW_AUTH_CONFIG_PATH=/path/to/config.ini mlflow server \
--backend-store-uri mysql+pymysql://admin:admin@localhost:3306/mlflow \
--host 127.0.0.1 --port 5000 --artifacts-destination s3://bucketname/ \
--app-name basic-auth
Kubeflow
머신러닝 워크플로우의 머신러닝 모델 학습부터 배포 단계까지 모든 작업에 필요한 도구와 환경을 쿠버네티스(Kubernetes) 위에서 쿠브플로우 컴포넌트로 제공한다.
쿠버네티스가 이미 동작하고 있는 시스템이라면 도입을 고려해볼만 하다.
Docs : https://www.kubeflow.org/docs/
Documentation
All of Kubeflow documentation
www.kubeflow.org
Anywhere you are running Kubernetes, you should be able to run Kubeflow.
kubeflow 또한 mlflow와 같이 다양한 ml 프레임워크에 대한 integration을 제공한다.

특징
- 쿠버네티스를 알아야 도입이 가능하다
- 쿠버네티스 Ingress 설정으로 호스트 하나에 다중 엔드포인트로 복수의 모델을 서빙할 수 있다.
(테스트 해보기 위해서는 쿠버네티스 환경이 필요하..다..)
gpt를 믿을 수는 없지만 쿠버네티스를 잘 모르기때문에… 어쩔 수 없이 물어본다.
쿠버네티스 파드를 띄우는 것처럼 모델을 yaml파일에 설정하고 서빙하는 형식인 듯하다.

기업 활용 사례
NAVER | AiSuite : Kubeflow를 통해 더 나은 AI 모델 서빙과 MLOps 실현하기
Kurly만의 MLOps 구축하기 - 쿠브플로우 도입기
→ 쿠브플로우
토스 | SLASH 22 - 물 흐르듯 자연스러운 ML 서비스 만들기
→ 자체 라이브러리로 제작
카카오뱅크의 MLOps / if(kakao)dev2022
→ airflow, 이미 개발자들이 airflow 개발 경험이 있음
→ 자체 플랫폼 제작
삼성 SDS | 쿠버네티스 기반의 AI 플랫폼: 쿠브플로우(Kubeflow)
어떤 오픈소스를 도입하는 것이 좋을지 선택해야할까
절대적으로 좋은 오픈소스는 존재하지 않는다.
현재 가지고 있는 시스템, 리소스에 따라서 선택하는게 최선이지 않을까.
토스나 라인처럼 ML 인력이 많다면 오픈소스를 이용하는 외에도 자체 제작을 하는 것도 좋은 선택지가 되는 것 처럼
뿌아앙
'AI' 카테고리의 다른 글
| Javascript로 AI모델 추론 - Read image as float32 with Javascript (0) | 2024.04.29 |
|---|---|
| Stable Diffusion WebUI 설치하고 사용해보기 - Apple Silicon (0) | 2023.12.27 |
| Bytes Are All you Need: Transformers Operating Directly On File Bytes 리뷰 (0) | 2023.06.12 |
| AutoEncoder 실습 (0) | 2023.05.18 |
| AE, AutoEncoder (0) | 2023.05.18 |