
최근 애플에서 발표한 논문으로 기존 이미지 모델에서 이미지 파일들을 RGB 형식으로 디코딩하여 모델에 사용했던 것과 달리 디코딩 과정없이 바이트 형식으로 모델 학습 및 추론을 하는 내용의 연구이다.
바이트 데이터를 이용하여 LLM Transformer를 이용하여 바이트 데이터를 토큰별로 임베딩하여 추론을 진행한다.
Bytes Are All You Need: Transformers Operating Directly On File Bytes
Modern deep learning approaches usually transform inputs into a modality-specific form. For example, the most common deep learning approach to image classification involves decoding image file bytes into an RGB tensor which is passed into a neural network.
arxiv.org
현대의 딥러닝 접근방식은 대게 특정한 형태의 입력값으로 변환시킨다. 예를 들어 대부분의 이미지 분류 모델은 이미지 파일을 RGB 형식의 텐서로 변환시키고 신경망에 넣는다. 대신에 이 연구에서는 추론 시 파일 데이터를 디코딩 하는 과정 없이 바이트 데이터를 직접적으로 이용하여 분류를 진행한다. 인공지능 모델의 입력값으로 바이트 데이터를 사용하는 것은 다양한 형태의 인풋을 가지는 모델의 개발을 가능하게 한다. ByteFormer는 ImageNet 분류에서 TIFF 형식의 데이터를 사용하여 DeiT-Ti와 유사한 Transformer backbone을 사용했을 때, 77.33%의 정확도를 보였다. 또한 수정 또는 하이퍼파라미터 튜닝 없이 Speech Commands v2 데이터 셋의 WAV 파일에 대해서 95.42%의 정확도를 보였다.
또한, Byteformer는 개인정보보호가 보장되는 추론에도 활용할 수 있다. ByteFormer는 정확도의 손실없이 일부 복호화된 입력값을 추론에 사용할 수 있다. 90%의 픽셀 채널을 마스킹하여 전체 이미지 생성을 방지하는 가상의 개인정보 보호 카메라를 이용한 추론에서 71.35%의 정확도를 보였다.
코드는 아래 링크에 공개될 예정이다.
https://github.com/apple/ml-cvnets/tree/main/examples/byteformer
1. Introduction
기존 연구방법의 단점
1. 모델의 입력값으로 사용하기 위해 각각의 데이터 형식마다 모델의 입력값의 맞는 형식으로 변환하는 수작업이 필요하다.
2. 데이터가 디코딩되어 분석됨으로써 프라이버시 침해 우려가 있다.
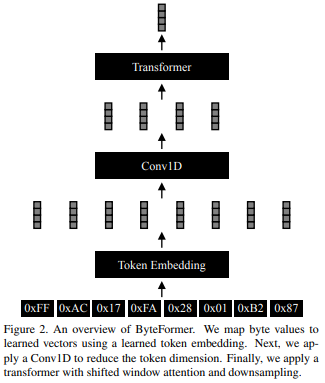
대다수의 데이터가 파일 바이트형식으로 저장되는 것에서 착안하여 바이트를 이용한 연구를 진행했고, 이를 ByteFormer라 한다.
ByteFormrer는 다양한 형태의 인풋을 받을 수 있어서 암호화의 수준까지는 아니나 변환 함수를 이용한 입력데이터를 복호화가 가능하다.
90%의 픽셀이 마스킹 된 이미지로도 71.35%의 정확도로 추론이 가능한 것을 증명하며 더 강력한 개인정보보호가 가능하다. ByteFormer는 마스킹된 픽셀의 위치 정보를 요구하지 않으며 표준 이미지 캡처를 방지하여 개인 정보를 유지한다.
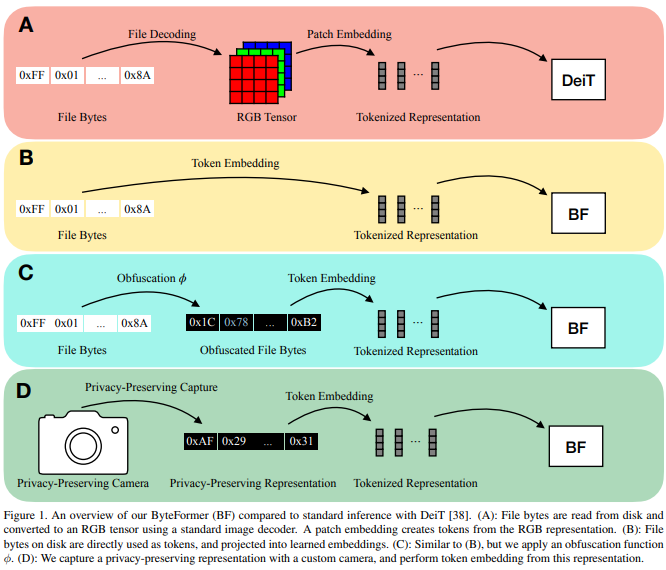
2. Related Work
Architectures With Multimodal Inputs
기존 네트워크에 다른 형식의 입력데이터를 feeding 하는 방식들이 연구되어 왔다. Perceiver Io에서 입력데이터를 [H X W, C] 버퍼로 로딩되어 들어가는 형식을 사용했으나, modality-specific 한 전처리 방법으로 처리된다.
Alternate image input Representations
Privacy-Reserving inference
Compressive Sensing
3. Overview of Common File Encoding
4. Methods
'AI' 카테고리의 다른 글
| Javascript로 AI모델 추론 - Read image as float32 with Javascript (0) | 2024.04.29 |
|---|---|
| Stable Diffusion WebUI 설치하고 사용해보기 - Apple Silicon (0) | 2023.12.27 |
| AutoEncoder 실습 (0) | 2023.05.18 |
| AE, AutoEncoder (0) | 2023.05.18 |
| Manifold Learning (0) | 2023.05.18 |