

idols = {
'그룹' : ['마마무', '에이핑크', '투피엠', '비투비'],
'멤버수' : [4, 6, 6, 6],
'데뷔년도' : ['2014', '2011', '2008', '2012'],
'소속사' : ['rbw', 'ist', 'jyp', 'cube']
}
df = pd.DataFrame(idols,
columns=['소속사', '데뷔년도', '그룹', '멤버수'],
index=['1', '2', '3', '4'])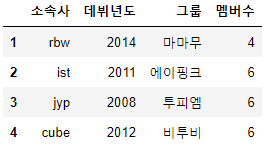
Column Indexing
하나의 column만 추출하기
group = df['그룹']
groupSeries 타입으로 반환된다.
1 마마무
2 에이핑크
3 투피엠
4 비투비
Name: 그룹, dtype: object이렇게 생성된 Series는 원복에서 복사된 것이 아니라
원본과 연결된 View이므로
변경하면 원본의 내용도 함께 변경된다.
group[0] = 'MAMAMOO'
display(df)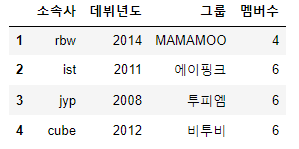
fancy indexing도 가능하다
f_indexing = df[['멤버수', '소속사']]
display(f_indexing)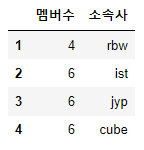
특정 컬럼의 값을 수정하는 것도 가능하다.
df['멤버수'] = 100 # broadcasting이 일어남
display(df)df['멤버수']의 결과는 Series이므로 100이라는 정수를 지정하면 broadcating이 일어나서
Series내의 데이터가 모두 해당 정수로 바뀌게 된다.
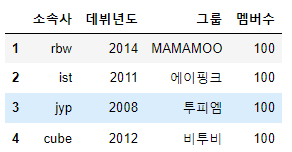
# 멤버수가 100명인건 이상하니까 다시 되돌려준다
df['멤버수'] = [4, 6, 6, 6]새로운 컬럼을 추가하는 것도 가능하다
dictionary에 새로운 key를 추가하는 것과 방법이 유사하다
기존에 없던 컬럼이 지정되면 새로 만들게 된다.
# 새로운 컬럼 추가
df['성별'] = ['f', 'f', 'm', 'm']
display(df)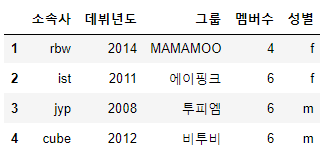
연산을 통해서 새로운 컬럼을 추가하는 것도 가능하다
지금 들고 있는 아이돌 예시는 적절하지 않지만 해볼 수 있다
물건의 가격 데이터를 다룰 때 쓸 수 있을 것 같다.
df['조정멤버'] = df['멤버수'] * 1.2
display(df)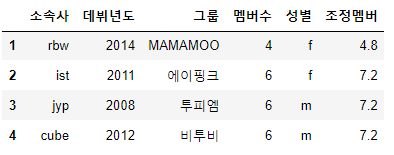
새로운 컬럼이 생성된 것을 확인할 수 있다.
말이 안되니까 해당 열을 삭제하도록 한다.
삭제
drop(index, axis, inplace)
axis : 축방향
inplace : 원본 수정 여부
column 삭제 : axis = 1
df.drop(['조정멤버'], axis=1, inplace=True)row 삭제 : axis = 0
df2=df.drop(['1'], axis=0, inplace=False)
display(df2)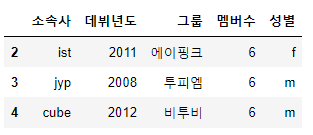
슬라이싱은 불가능하다!
df[['소속사':'그룹']] Input In [32]
df[['소속사':'그룹']]
^
SyntaxError: invalid syntax-> fancy index을 이용해야 한다
df[['소속사', '데뷔년도', '그룹']]
row indexing
열방향 인덱싱을 슬라이싱만 가능하다
df[0]와 같이 단일 행만 추출할 수 없다.
하지만 슬라이싱은 가능하다
df[0:2]
슬라이싱의 결과는 원본과 연결된 view를 보여준다.
df['1':'2']와 같은 지정 인덱스로도 슬라이싱이 가능하다
하지만 fancy indexing은 불가능하다.
(ex. df[[0,2]])
열과 행의 구분이 불가능하기 때문이다
따라서 row인덱싱은 loc method를 이용한다.
df.loc['index']
단 loc을 이용할 때는 지정인덱스만 사용할 수 있다.
df.loc['1'] # type = Series소속사 rbw
데뷔년도 2014
그룹 MAMAMOO
멤버수 4
성별 f
Name: 1, dtype: object컬럼명이 인덱스로 나타난다는 특징이 있다.
print(s.values)
print(s.index) # 컬럼명이 index로 나타난다.['rbw' '2014' 'MAMAMOO' 4 'f']
Index(['소속사', '데뷔년도', '그룹', '멤버수', '성별'], dtype='object')df.loc[['1','3']] 이와 같은 fancy indexing도 가능하다
- df.loc[행, 열] : 요소가 두 개있으면 행과 열의 순서로 인식한다.
- df.loc[행] : 요소가 하나 있으면 index, 즉 행 indexing으로 인식한다
숫자 인덱스를 사용해서 row indexing을 하려면
iloc을 이용하면 된다
df.iloc[0]소속사 rbw
데뷔년도 2014
그룹 마마무
멤버수 4
Name: 1, dtype: objectdf.loc['2':'3',['그룹', '소속사']] # 지정 인덱스로 슬라이싱, fancy indexing 모두 가능!!
boolean indexing
사용할 데이터
student = {
'학과' : ['철학', '음악', '체육', '국어국문'],
'이름' : ['홍길동', '아이유', '김연아', '신사임당'],
'학점' : [1.4, 3.1, 4.3, 2.7],
'학년' : [1, 3, 2, 4]
}
new_df = pd.DataFrame(student,
index=['one', 'two', 'three', 'four'])
new_df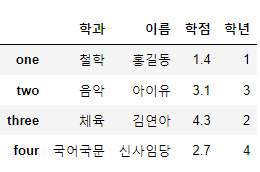
# 학점이 3.0 이상인 학생의 학과와 이름을 출력하세요
new_df[new_df['학점']>3.0][['이름','학과']]
new_df['학점']>3.0one False
two True
three True
four False
Name: 학점, dtype: bool
'Programming > Pandas' 카테고리의 다른 글
| [pandas] read_csv 'utf-8' error (1) | 2022.03.21 |
|---|---|
| [Pandas] Movie Lens Data를 이용한 EDA 실습 (1) | 2022.03.21 |
| [pandas] DataFrame Merge, Mapping, Grouping (0) | 2022.03.21 |
| [pandas] 여러가지 resource를 이용하여 DataFrame 생성하기 (csv, sql, api, json) (0) | 2022.03.17 |
| [pandas] 데이터 조작 및 분석을 위한 python module - pandas (0) | 2022.03.17 |