
TensorRT는 만들 딥러닝 모델을 최적하하고, 모델의 크기를 줄이거나 gpu 환경에 최적화시켜 계산 속도를 높이는 등의 목적을 위해 사용하는 Nvidia에서 개발한 SDK로 딥러닝 모델의 배포를 위해 쓰인다.
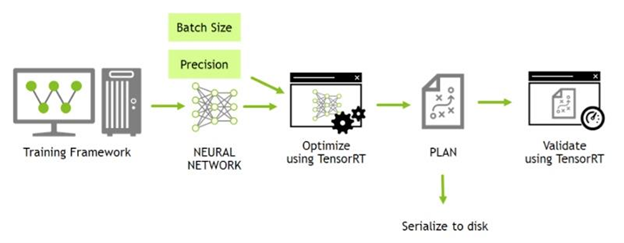
TensorRT의 WorkFlow는 다음과 같다


TensorRT를 처음 접하자마자 이 그림을 보면 이해가 안될 수 있지만 어느정도 해보고나서 본다면 워크플로우가 아주 잘 설명된 그림인 것을 알 수 있다.
TensorFlow나 Pytorch 등 다양한 프레임워크를 지원한다.
나는 pytorch로 빌드한 모델을 Onnx모델로 먼저 변환한 후 onnx를 다시 TensorRT 모델로 바꾸었다.
ONNX 변환은 일반적으로 ONNX 모델을 TensorRT 엔진으로 자동 변환하는 가장 성능이 좋은 방법이다.
ONNX란?
ONNX(Open Neural Network Exchange)는 Tensorflow, PyTorch 와 같은 서로 다른 DNN 프레임워크 환경에서 만들어진 모델들을 서로 호환해서 사용할 수 있도록 도와주는 공유 플랫폼
torch.onnx.export() option
torch.onnx.export Signature: torch.onnx.export( model: 'Union[torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction]', args: 'Union[Tuple[Any, ...], torch.Tensor]', f: 'Union[str, io.BytesIO]', export_params: 'bool' = True, verbose: 'bool' = Fa
stop-thinking-start-now.tistory.com
TensorRT is a high-performance deep learning inference library developed by NVIDIA for optimizing and deploying deep neural networks (DNNs) on NVIDIA GPUs. It provides a set of tools and libraries to optimize trained neural networks for deployment on NVIDIA hardware.
TensorRT works by optimizing the computation graph of a neural network model and using mixed-precision arithmetic to speed up the calculations. It also supports dynamic tensor shapes and batch sizes, which allows for more efficient use of GPU resources. Additionally, TensorRT includes features such as layer fusion, precision calibration, and dynamic tensor memory management to further optimize inference performance.
TensorRT is typically used in production environments where low latency and high throughput are critical requirements, such as in self-driving cars, video analytics, and natural language processing applications. By using TensorRT, developers can significantly improve the performance of their DNNs on NVIDIA GPUs, leading to faster and more accurate inference results.
TensorRT는 NVIDIA에서 개발한 고성능 딥러닝 추론 라이브러리로, NVIDIA GPU에서 교육된 딥 뉴럴 네트워크(DNN)를 최적화하고 배포하기 위한 도구 및 라이브러리 세트를 제공합니다.
TensorRT는 DNN 모델의 계산 그래프를 최적화하고 혼합 정밀도 산술을 사용하여 계산 속도를 높이는 방식으로 작동합니다. 또한 동적 텐서 형태와 배치 크기를 지원하여 GPU 리소스를 더 효율적으로 사용할 수 있습니다. 더불어 TensorRT는 레이어 퓨전, 정밀도 보정 및 동적 텐서 메모리 관리와 같은 기능을 포함하여 추론 성능을 더욱 최적화합니다.
TensorRT는 자율 주행 자동차, 비디오 분석 및 자연어 처리와 같이 낮은 대기 시간과 높은 처리량이 필수적인 제품 환경에서 주로 사용됩니다. TensorRT를 사용하면 개발자는 NVIDIA GPU에서 DNN의 성능을 크게 향상시켜 더 빠르고 정확한 추론 결과를 얻을 수 있습니다.
- ChatGPT -
Quick Start Guide :: NVIDIA Deep Learning TensorRT Documentation
This section contains instructions for installing TensorRT from the Python Package Index. Note: When installing TensorRT from the Python Package Index, you’re not required to install TensorRT from a .tar, .deb, or .rpm package. All required libraries are
docs.nvidia.com
Speeding Up Deep Learning Inference Using NVIDIA TensorRT (Updated) | NVIDIA Technical Blog
This post was updated July 20, 2021 to reflect NVIDIA TensorRT 8.0 updates. NVIDIA TensorRT is an SDK for deep learning inference. TensorRT provides APIs and parsers to import trained models from all…
developer.nvidia.com
'Programming > TensorRT' 카테고리의 다른 글
| trtexec 옵션 및 예시 (0) | 2023.03.23 |
|---|---|
| 데이터 직렬화(Serialize)와 역직렬화(Deserialize) (0) | 2023.03.21 |
| [TensorRT] *.engine 과 *.trt 차이점 (0) | 2023.03.21 |
| pycuda 개념 및 사용 예시 (1) | 2023.03.21 |
| TensorRT 환경 설정: 도커 컨테이너 (0) | 2023.03.14 |