
*.pt 모델을 *.onnx로 변환하고 최종적으로 tensorRT *.engine 까지 변환하는 테스트를 위해
파이토치 공부하는 겸 모델을 하나 빌드하기로 했다.
간단하게 CNN 레이어 몇 개 해서 간단한 모델을 작성해볼 수 있지만, 이건 해봤고
pretrained net 가지고와서 finetuning 하는 건 torch로 안해봐서 해보기로 했다.
사용할 데이터 셋은 torchvision dataset에서 제공해주는 CIFAR10
import
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets
import torch.optim as optim
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import numpy as np
import time
import copy
from tqdm.auto import tqdm
############
import onnx
import tensorrt as trt
import onnxruntime as ort토치모델빌드를 위해서는 주석 전 위에 패키지만 import 해도 된다
config
BATCH = 64
LR = 1e-4
MOMENTUM = 0.9
EPOCH = 300
FINEEPOCH=200
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
labels_map = {
0: "plane",
1: "car",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck"
}
load dataset and set data loader
training_data = datasets.CIFAR10(
root='data',
train=True,
download=True,
transform=ToTensor() # TODO
)
test_data = datasets.CIFAR10(
root='data',
train=False,
download=True,
transform=ToTensor()
)
# dataloader
train_dataloader = DataLoader(training_data, batch_size = BATCH, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size = BATCH, shuffle=True)visualize dataset iter from data loader
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
# Feature batch shape: torch.Size([64, 3, 32, 32])
print(f"Labels batch shape: {train_labels.size()}")
# Labels batch shape: torch.Size([64])
fig = plt.figure()
for i in range(9):
train_features, train_labels = next(iter(train_dataloader))
ax = fig.add_subplot(3,3, i+1)
ax.imshow(train_features[0].permute(1,2,0))
ax.set_title(labels_map[train_labels[0].item()])
plt.tight_layout()
plt.show()
ResNet 50
from torchvision.models import resnet50, ResNet50_Weights
from torchsummary import summary
weights = ResNet50_Weights.DEFAULT
resnet = resnet50(weights=weights)torchsummary는 파이토치 모델을 케라스 스타일로 출력해주는 툴이다.
$ pip install torch_summary
torch의 Resnet50은 ImageNet으로 사전학습되어있어 출력 클래스가 1000이다
dir()로 확인해볼 수 있다.
dir(ResNet50_Weights)['IMAGENET1K_V1',
'IMAGENET1K_V2',
'__class__',
'__doc__',
'__members__',
'__module__']
모델을 확인해보면
summary(resnet, (3,32,32))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
├─Conv2d: 1-1 [-1, 64, 16, 16] 9,408
├─BatchNorm2d: 1-2 [-1, 64, 16, 16] 128
├─ReLU: 1-3 [-1, 64, 16, 16] --
├─MaxPool2d: 1-4 [-1, 64, 8, 8] --
├─Sequential: 1-5 [-1, 256, 8, 8] --
| └─Bottleneck: 2-1 [-1, 256, 8, 8] --
| | └─Conv2d: 3-1 [-1, 64, 8, 8] 4,096
| | └─BatchNorm2d: 3-2 [-1, 64, 8, 8] 128
| | └─ReLU: 3-3 [-1, 64, 8, 8] --
| | └─Conv2d: 3-4 [-1, 64, 8, 8] 36,864
| | └─BatchNorm2d: 3-5 [-1, 64, 8, 8] 128
| | └─ReLU: 3-6 [-1, 64, 8, 8] --
| | └─Conv2d: 3-7 [-1, 256, 8, 8] 16,384
| | └─BatchNorm2d: 3-8 [-1, 256, 8, 8] 512
| | └─Sequential: 3-9 [-1, 256, 8, 8] 16,896
| | └─ReLU: 3-10 [-1, 256, 8, 8] --
| └─Bottleneck: 2-2 [-1, 256, 8, 8] --
| | └─Conv2d: 3-11 [-1, 64, 8, 8] 16,384
| | └─BatchNorm2d: 3-12 [-1, 64, 8, 8] 128
| | └─ReLU: 3-13 [-1, 64, 8, 8] --
| | └─Conv2d: 3-14 [-1, 64, 8, 8] 36,864
| | └─BatchNorm2d: 3-15 [-1, 64, 8, 8] 128
| | └─ReLU: 3-16 [-1, 64, 8, 8] --
| | └─Conv2d: 3-17 [-1, 256, 8, 8] 16,384
| | └─BatchNorm2d: 3-18 [-1, 256, 8, 8] 512
| | └─ReLU: 3-19 [-1, 256, 8, 8] --
| └─Bottleneck: 2-3 [-1, 256, 8, 8] --
| | └─Conv2d: 3-20 [-1, 64, 8, 8] 16,384
| | └─BatchNorm2d: 3-21 [-1, 64, 8, 8] 128
| | └─ReLU: 3-22 [-1, 64, 8, 8] --
| | └─Conv2d: 3-23 [-1, 64, 8, 8] 36,864
| | └─BatchNorm2d: 3-24 [-1, 64, 8, 8] 128
| | └─ReLU: 3-25 [-1, 64, 8, 8] --
| | └─Conv2d: 3-26 [-1, 256, 8, 8] 16,384
| | └─BatchNorm2d: 3-27 [-1, 256, 8, 8] 512
| | └─ReLU: 3-28 [-1, 256, 8, 8] --
├─Sequential: 1-6 [-1, 512, 4, 4] --
| └─Bottleneck: 2-4 [-1, 512, 4, 4] --
| | └─Conv2d: 3-29 [-1, 128, 8, 8] 32,768
| | └─BatchNorm2d: 3-30 [-1, 128, 8, 8] 256
| | └─ReLU: 3-31 [-1, 128, 8, 8] --
| | └─Conv2d: 3-32 [-1, 128, 4, 4] 147,456
| | └─BatchNorm2d: 3-33 [-1, 128, 4, 4] 256
| | └─ReLU: 3-34 [-1, 128, 4, 4] --
| | └─Conv2d: 3-35 [-1, 512, 4, 4] 65,536
| | └─BatchNorm2d: 3-36 [-1, 512, 4, 4] 1,024
| | └─Sequential: 3-37 [-1, 512, 4, 4] 132,096
| | └─ReLU: 3-38 [-1, 512, 4, 4] --
| └─Bottleneck: 2-5 [-1, 512, 4, 4] --
| | └─Conv2d: 3-39 [-1, 128, 4, 4] 65,536
| | └─BatchNorm2d: 3-40 [-1, 128, 4, 4] 256
| | └─ReLU: 3-41 [-1, 128, 4, 4] --
| | └─Conv2d: 3-42 [-1, 128, 4, 4] 147,456
| | └─BatchNorm2d: 3-43 [-1, 128, 4, 4] 256
| | └─ReLU: 3-44 [-1, 128, 4, 4] --
| | └─Conv2d: 3-45 [-1, 512, 4, 4] 65,536
| | └─BatchNorm2d: 3-46 [-1, 512, 4, 4] 1,024
| | └─ReLU: 3-47 [-1, 512, 4, 4] --
| └─Bottleneck: 2-6 [-1, 512, 4, 4] --
| | └─Conv2d: 3-48 [-1, 128, 4, 4] 65,536
| | └─BatchNorm2d: 3-49 [-1, 128, 4, 4] 256
| | └─ReLU: 3-50 [-1, 128, 4, 4] --
| | └─Conv2d: 3-51 [-1, 128, 4, 4] 147,456
| | └─BatchNorm2d: 3-52 [-1, 128, 4, 4] 256
| | └─ReLU: 3-53 [-1, 128, 4, 4] --
| | └─Conv2d: 3-54 [-1, 512, 4, 4] 65,536
| | └─BatchNorm2d: 3-55 [-1, 512, 4, 4] 1,024
| | └─ReLU: 3-56 [-1, 512, 4, 4] --
| └─Bottleneck: 2-7 [-1, 512, 4, 4] --
| | └─Conv2d: 3-57 [-1, 128, 4, 4] 65,536
| | └─BatchNorm2d: 3-58 [-1, 128, 4, 4] 256
| | └─ReLU: 3-59 [-1, 128, 4, 4] --
| | └─Conv2d: 3-60 [-1, 128, 4, 4] 147,456
| | └─BatchNorm2d: 3-61 [-1, 128, 4, 4] 256
| | └─ReLU: 3-62 [-1, 128, 4, 4] --
| | └─Conv2d: 3-63 [-1, 512, 4, 4] 65,536
| | └─BatchNorm2d: 3-64 [-1, 512, 4, 4] 1,024
| | └─ReLU: 3-65 [-1, 512, 4, 4] --
├─Sequential: 1-7 [-1, 1024, 2, 2] --
| └─Bottleneck: 2-8 [-1, 1024, 2, 2] --
| | └─Conv2d: 3-66 [-1, 256, 4, 4] 131,072
| | └─BatchNorm2d: 3-67 [-1, 256, 4, 4] 512
| | └─ReLU: 3-68 [-1, 256, 4, 4] --
| | └─Conv2d: 3-69 [-1, 256, 2, 2] 589,824
| | └─BatchNorm2d: 3-70 [-1, 256, 2, 2] 512
| | └─ReLU: 3-71 [-1, 256, 2, 2] --
| | └─Conv2d: 3-72 [-1, 1024, 2, 2] 262,144
| | └─BatchNorm2d: 3-73 [-1, 1024, 2, 2] 2,048
| | └─Sequential: 3-74 [-1, 1024, 2, 2] 526,336
| | └─ReLU: 3-75 [-1, 1024, 2, 2] --
| └─Bottleneck: 2-9 [-1, 1024, 2, 2] --
| | └─Conv2d: 3-76 [-1, 256, 2, 2] 262,144
| | └─BatchNorm2d: 3-77 [-1, 256, 2, 2] 512
| | └─ReLU: 3-78 [-1, 256, 2, 2] --
| | └─Conv2d: 3-79 [-1, 256, 2, 2] 589,824
| | └─BatchNorm2d: 3-80 [-1, 256, 2, 2] 512
| | └─ReLU: 3-81 [-1, 256, 2, 2] --
| | └─Conv2d: 3-82 [-1, 1024, 2, 2] 262,144
| | └─BatchNorm2d: 3-83 [-1, 1024, 2, 2] 2,048
| | └─ReLU: 3-84 [-1, 1024, 2, 2] --
| └─Bottleneck: 2-10 [-1, 1024, 2, 2] --
| | └─Conv2d: 3-85 [-1, 256, 2, 2] 262,144
| | └─BatchNorm2d: 3-86 [-1, 256, 2, 2] 512
| | └─ReLU: 3-87 [-1, 256, 2, 2] --
| | └─Conv2d: 3-88 [-1, 256, 2, 2] 589,824
| | └─BatchNorm2d: 3-89 [-1, 256, 2, 2] 512
| | └─ReLU: 3-90 [-1, 256, 2, 2] --
| | └─Conv2d: 3-91 [-1, 1024, 2, 2] 262,144
| | └─BatchNorm2d: 3-92 [-1, 1024, 2, 2] 2,048
| | └─ReLU: 3-93 [-1, 1024, 2, 2] --
| └─Bottleneck: 2-11 [-1, 1024, 2, 2] --
| | └─Conv2d: 3-94 [-1, 256, 2, 2] 262,144
| | └─BatchNorm2d: 3-95 [-1, 256, 2, 2] 512
| | └─ReLU: 3-96 [-1, 256, 2, 2] --
| | └─Conv2d: 3-97 [-1, 256, 2, 2] 589,824
| | └─BatchNorm2d: 3-98 [-1, 256, 2, 2] 512
| | └─ReLU: 3-99 [-1, 256, 2, 2] --
| | └─Conv2d: 3-100 [-1, 1024, 2, 2] 262,144
| | └─BatchNorm2d: 3-101 [-1, 1024, 2, 2] 2,048
| | └─ReLU: 3-102 [-1, 1024, 2, 2] --
| └─Bottleneck: 2-12 [-1, 1024, 2, 2] --
| | └─Conv2d: 3-103 [-1, 256, 2, 2] 262,144
| | └─BatchNorm2d: 3-104 [-1, 256, 2, 2] 512
| | └─ReLU: 3-105 [-1, 256, 2, 2] --
| | └─Conv2d: 3-106 [-1, 256, 2, 2] 589,824
| | └─BatchNorm2d: 3-107 [-1, 256, 2, 2] 512
| | └─ReLU: 3-108 [-1, 256, 2, 2] --
| | └─Conv2d: 3-109 [-1, 1024, 2, 2] 262,144
| | └─BatchNorm2d: 3-110 [-1, 1024, 2, 2] 2,048
| | └─ReLU: 3-111 [-1, 1024, 2, 2] --
| └─Bottleneck: 2-13 [-1, 1024, 2, 2] --
| | └─Conv2d: 3-112 [-1, 256, 2, 2] 262,144
| | └─BatchNorm2d: 3-113 [-1, 256, 2, 2] 512
| | └─ReLU: 3-114 [-1, 256, 2, 2] --
| | └─Conv2d: 3-115 [-1, 256, 2, 2] 589,824
| | └─BatchNorm2d: 3-116 [-1, 256, 2, 2] 512
| | └─ReLU: 3-117 [-1, 256, 2, 2] --
| | └─Conv2d: 3-118 [-1, 1024, 2, 2] 262,144
| | └─BatchNorm2d: 3-119 [-1, 1024, 2, 2] 2,048
| | └─ReLU: 3-120 [-1, 1024, 2, 2] --
├─Sequential: 1-8 [-1, 2048, 1, 1] --
| └─Bottleneck: 2-14 [-1, 2048, 1, 1] --
| | └─Conv2d: 3-121 [-1, 512, 2, 2] 524,288
| | └─BatchNorm2d: 3-122 [-1, 512, 2, 2] 1,024
| | └─ReLU: 3-123 [-1, 512, 2, 2] --
| | └─Conv2d: 3-124 [-1, 512, 1, 1] 2,359,296
| | └─BatchNorm2d: 3-125 [-1, 512, 1, 1] 1,024
| | └─ReLU: 3-126 [-1, 512, 1, 1] --
| | └─Conv2d: 3-127 [-1, 2048, 1, 1] 1,048,576
| | └─BatchNorm2d: 3-128 [-1, 2048, 1, 1] 4,096
| | └─Sequential: 3-129 [-1, 2048, 1, 1] 2,101,248
| | └─ReLU: 3-130 [-1, 2048, 1, 1] --
| └─Bottleneck: 2-15 [-1, 2048, 1, 1] --
| | └─Conv2d: 3-131 [-1, 512, 1, 1] 1,048,576
| | └─BatchNorm2d: 3-132 [-1, 512, 1, 1] 1,024
| | └─ReLU: 3-133 [-1, 512, 1, 1] --
| | └─Conv2d: 3-134 [-1, 512, 1, 1] 2,359,296
| | └─BatchNorm2d: 3-135 [-1, 512, 1, 1] 1,024
| | └─ReLU: 3-136 [-1, 512, 1, 1] --
| | └─Conv2d: 3-137 [-1, 2048, 1, 1] 1,048,576
| | └─BatchNorm2d: 3-138 [-1, 2048, 1, 1] 4,096
| | └─ReLU: 3-139 [-1, 2048, 1, 1] --
| └─Bottleneck: 2-16 [-1, 2048, 1, 1] --
| | └─Conv2d: 3-140 [-1, 512, 1, 1] 1,048,576
| | └─BatchNorm2d: 3-141 [-1, 512, 1, 1] 1,024
| | └─ReLU: 3-142 [-1, 512, 1, 1] --
| | └─Conv2d: 3-143 [-1, 512, 1, 1] 2,359,296
| | └─BatchNorm2d: 3-144 [-1, 512, 1, 1] 1,024
| | └─ReLU: 3-145 [-1, 512, 1, 1] --
| | └─Conv2d: 3-146 [-1, 2048, 1, 1] 1,048,576
| | └─BatchNorm2d: 3-147 [-1, 2048, 1, 1] 4,096
| | └─ReLU: 3-148 [-1, 2048, 1, 1] --
├─AdaptiveAvgPool2d: 1-9 [-1, 2048, 1, 1] --
├─Linear: 1-10 [-1, 1000] 2,049,000
==========================================================================================
Total params: 25,557,032
Trainable params: 25,557,032
Non-trainable params: 0
Total mult-adds (M): 135.20
==========================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 3.47
Params size (MB): 97.49
Estimated Total Size (MB): 100.97
==========================================================================================위와 같이 나오고 마지막에서 Linear shape이 [-1, 1000]인 것을 확인할 수 있고
Total params와 Trainable params의 수도 동일한 것을 확인할 수 있다.
freezing layers
tensorfow 2.0 에서 layer 마다 trainable=False로 지정해준 것처럼 torch에서는 requires_grad 를 통해 학습여부(freezing 여부)를 설정할 수 있다.
for param in resnet.parameters():
# freeze trainig
param.requires_grad = False이 코드 실행 후 다시 summary를 해보면 trainabel params의 수가 바뀐 것을 확인 할 수 있다.
change fc layer
그리고 1000개 클래스에 맞춰져있는 fully connected layer를 바꾸어주어야한다.
# replace fc layer
resnet.fc = nn.Linear(resnet.fc.in_features, 10)
Training
트레이닝 코드는 torch docs에서 가지고 와서 다른 사전학습모델을 사용하는 부분은 제외하고 tqdm을 추가했다.
early stopping이랑 train acc, loss도 기록하고 싶은데 그건 다음에 training code를 공부할 때 하기로!
dataloaders_dict = {
'train' : train_dataloader,
'valid' : test_dataloader
}
def train(model, dataloaders, criterion, optimizer, num_epochs=25):
since = time.time()
model = model.to(device)
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in tqdm(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'valid':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_historyoptimizer = optim.SGD(resnet.parameters(), lr=LR, momentum=MOMENTUM)
criterion = nn.CrossEntropyLoss()
resnet, val_acc_hist = train(resnet, dataloaders_dict, criterion, optimizer, num_epochs=EPOCH)
plot history
ohist = [h.cpu().numpy() for h in val_acc_hist]
plt.plot(ohist)
plt.title('Validation Accuracy')
plt.show()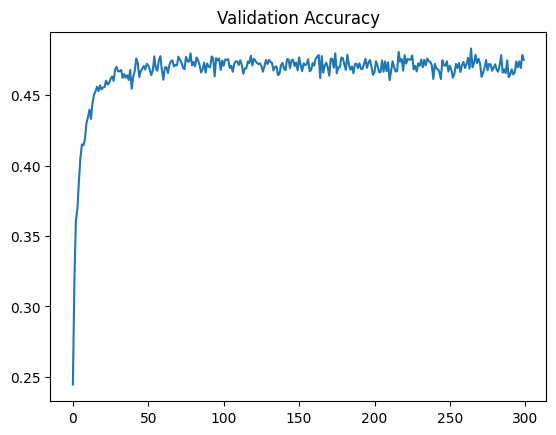
정확도가 향상이 안되서 epoch을 길게했는데도 정확도가 향상되지 않았다
다 하고 나니 간과했던 점이 하나있었는데 fc layer 하나만 trainable 했고 나머지는 다 freeze 시켜둔 상태에서 학습을 진행하니 학습이 제대로 진행될리가 없었다.
탑 레이어 몇 개를 더 풀어줬어야 했다.
finetune
for param in resnet.parameters():
# freeze trainig
param.requires_grad = True
LR = LR / 10finetuning 단계에서는 모든 레이어의 동결을 풀고 learning rate를 낮추어 학습을 한다.
optimizer = optim.SGD(resnet.parameters(), lr=LR, momentum=MOMENTUM)
criterion = nn.CrossEntropyLoss()
resnet, fine_acc_hist = train(resnet, dataloaders_dict, criterion, optimizer, num_epochs=FINEEPOCH)추가로 200 epoch 돌려줬는데 정확도가 90을 안넘어서 추가로 100epoch 더 학습해줬다.
resnet, fine_acc_hist_2 = train(resnet, dataloaders_dict, criterion, optimizer, num_epochs=100)
nhist_2 = [h.cpu().numpy() for h in fine_acc_hist_2]모델 빌딩 방법만 학습하자 하다 보니 모델 학습과정이 아주 엉망이다
plot history
hist = ohist + nhist + nhist_2
plt.plot(hist)
plt.title('Validation Accuracy')
plt.plot([300, 300], plt.ylim())
plt.show()
Model Save
torch.save(resnet, 'resnet_CIFAR10_epoch600.pt')모델을 통째로 저장해줬다.
Model Load
model = torch.load('resnet_CIFAR10_epoch600.pt')
model.eval() # inference mode
Inference Test
data, label = next(iter(test_dataloader))
model = model.to(device)
input_img = data[:9, :].to(device)
output = model(input_img)
output = output.to('cpu')
output = [torch.argmax(o) for o in output]
fig = plt.figure()
for i in range(9):
ax = fig.add_subplot(3,3, i+1)
ax.imshow(input_img[i].to('cpu').permute(1,2,0))
ax.set_title(f'{labels_map[output[i].item()]} : {labels_map[label[i].item()]}')
plt.suptitle('Torch Inference Result')
plt.tight_layout()
plt.show()
이렇게 구성한 모델을
1. torch.onnx.export() 를 이용하여 먼저 onnx 모델로 바꾸어준 후
torch.onnx.export() option
torch.onnx.export Signature: torch.onnx.export( model: 'Union[torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction]', args: 'Union[Tuple[Any, ...], torch.Tensor]', f: 'Union[str, io.BytesIO]', export_params: 'bool' = True, verbose: 'bool' = Fa
stop-thinking-start-now.tistory.com
2. tensorrt를 이용해서 engine 파일로 바꾸어주면 경량화, 최적화된 모델을 만들 수 있다.
[TensorRT 변환] ONNX2TensorRT(transformation and inference)
TensorRT serialize & deserialize code with using dynamic batch TensorRT serialize & deserialize code with using dynamic batch - tensorrt.py gist.github.com 파이썬으로 Onnx 파일을 불러와 engine파일로 직렬화하여 변환하여 저장하고,
stop-thinking-start-now.tistory.com
'Programming > Pytorch' 카테고리의 다른 글
| torch 모델 저장 및 불러오기 (0) | 2023.03.01 |
|---|---|
| torch.onnx.export() option (1) | 2023.02.28 |
| [yolov7] hyperparameter evolve : Index Error: index 30 is out of bounds for axis 0 with size 30 (0) | 2023.02.22 |